



Кодовые таблицы используются для обозначения букв в компьютерных технологиях. Краткое описание типов таблиц символов и их использование описано в этой статье.
Что такое кодовая таблица
Известно, что числа в компьютере представляются в двоичной форме, как набор нулей и единиц. Для этого разработаны специальные методики преобразования числовых значений в двоичную последовательность. Как компьютер обрабатывает текстовую информацию – предложения, слова и буквы? Точно так же, как числа – в виде последовательности нулей и единиц.
Чтобы представить букву в компьютере, она заменяется числовым эквивалентом, а затем преобразуется в двоичный код. Каждая буква имеет свой номер. Все буквы с их числовыми эквивалентами компилируются в таблицу кодов символов, которую можно назвать ASCII, Unicode, KOI-7, KOI-8, Windows-1251.
Таблица ASCII
Самой первой системой кодирования текстовой информации была ASCII (Американский стандартный код обмена информацией).
Таблица ASCII была разработана в США в шестидесятых годах прошлого века. Появление такой единой системы кодирования символов было продиктовано необходимостью реализации компьютерного взаимодействия и обмена информацией. В то время каждый производитель компьютеров самостоятельно представлял буквы, цифры и управляющие коды. Только специалисты IBM использовали девять различных наборов кодировок символов.
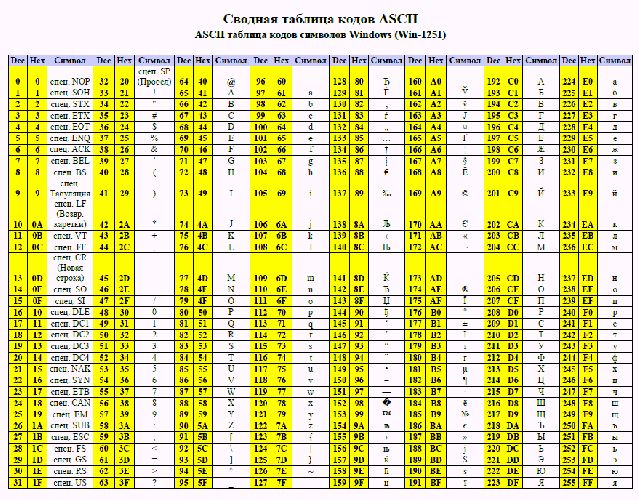
Идея создания единой стандартизированной системы кодирования символов в виде числовых эквивалентов принадлежит американскому специалисту в области информационных технологий Роберту Уильяму Бемеру. Это он придумал экранирующий символ «Esc», обозначающий то, что следующий после него символ, имеет некоторое другое значение, не такое как ему назначено в таблице ASCII.

Изначально таблица использовалась для кодирования всего 128 символов, затем ее расширили до 256 символов. Первые тридцать два символа таблицы ASCI не имеют печатного эквивалента и используются для управления. Числа в диапазоне 32–127 предназначены для кодирования латинских букв верхнего и нижнего регистра, цифр и знаков препинания.
Знак пробела имеет код 32 и также является печатным символом. Проверить соответствие символа печатному коду легко. Для этого можно воспользоваться простейшим текстовым редактором Блокнот в группе программ Стандартные операционной системы Windows. Нажав одновременно функциональную клавишу Alt и введя код символа – десятичное число, в окне редактора на месте расположения курсора будет напечатан соответствующий символ.
Национальные версии таблицы ASCII
Таблица ASCII в диапазоне символов от 0 до 127 остается неизменной для всех программ. Диапазон значений кода от 128 до 255 может варьироваться в зависимости от языка и национальных особенностей.
Существуют разные национальные версии системы кодирования. Для кодирования букв русского алфавита используется:
- IBM cp866
- Вин-1251
- КОИ8
Unicode
Unicode — это отраслевой стандарт кодирования символов во всех письменных языках мира. Он был предложен в 1991 году некоммерческой организацией Unicode Consortium.

Кодовое пространство Unicode разделено на несколько регионов. Диапазон значений кода от 0 до 127 полностью дублирует кодовую систему ASCII. Затем есть области с символами на разных языках, знаками препинания и некоторыми техническими символами.
Юникод имеет несколько форм: UTF-8, UTF-16 и UTF-32.
Что мы узнали?
Для представления символьных значений в компьютере используются таблицы кодировки символов. Каждому символу в такой таблице соответствует числовое значение. Использование стандартизированных кодовых таблиц позволило обеспечить взаимодействие и обмен информацией между компьютерными системами.




Комментирование закрыто